NYC Tree Census 2015
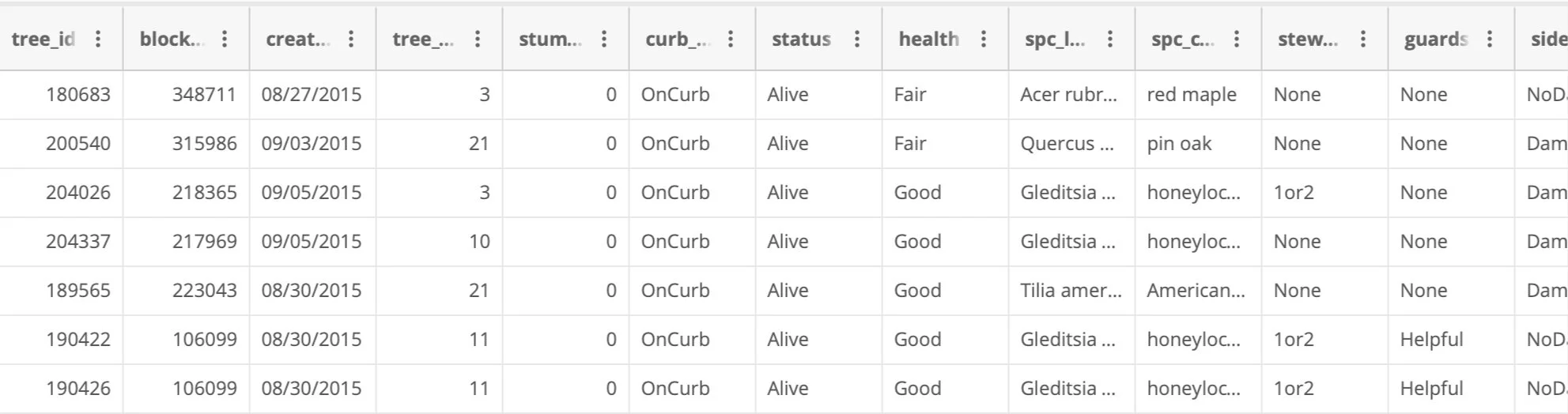
In this project I analyze the results from the NYC Tree Census conducted in 2015. In the first Python program, I use the csv module to parse through the original dataset, and exclude records that were not of interest to me. I use the results from the first program in the second program, and further clean the data using the pandas module. The second Python program produces a clean dataset, containing only records for trees that are alive and in Manhattan, and summary statistics for these records.
*It is possible and likely that my findings are incorrect. When I completed this project, I did not have access to a Hadoop Cluster, which has the ability to store and process large datasets. My laptop struggled to download and process the original dataset, so even though my results aren’t totally reliable, it was still a fun exercise!
Perhaps in the future, I can create a new analytic that will run entirely on a Hadoop Cluster!
Output from second program- results & summary statistics


View files
or download
program to clean dataset (.py) program for summary statistics (.py)
*didn’t include links to download datasets because they are large and you wouldn’t want to accidentally download them lol.